


Reader questions: self-driving, inflation, and our robot overlords
Today is the last day to subscribe at an annual rate of $49.50!

When I re-launched Full Stack Economics on Substack last month, I announced a special launch discount: $49.50 for an annual subscription. Today is the last day to get that deal. Starting tomorrow, an annual subscription will cost $66. And you’ll want to be a paying subscriber because I’m soon going to start putting some of my pieces behind a paywall.
Full Stack Economics is a full-time effort for me. I don’t have any investors or donors, and I don’t show any ads. Hence, I depend on financial support from readers. If you’ve been enjoying my work, please consider upgrading to a paid subscription today.
One regular feature paying subscribers will get is mailbag posts like this one, where I answer questions from readers. This post is open to everyone, but the next one will be limited to paying subscribers. So don’t miss out—please subscribe now.
What about simpler applications for self-driving?
Patrick Spoutz wants to know: “Why aren't we seeing ‘simple use case AV tech?’ What about "Tesla Summon that actually works for an off-site parking garage a few blocks away?" Or, "closed-access one lane road with AV busses" instead of a light rail train? These are all much simpler use cases and we just aren't seeing much happening here. I would guess that Waymo or Cruise could do either above with current tech, but must just have their eye on the big prize and dont feel this is worth their time.”
I think the short answer is that simple use cases often turn out not to be so simple in practice. It would be pretty easy to build a self-parking system that works 99 percent of the time. But a driverless system that fails 1 percent of the time is worse than useless in the real world. Even if you can guarantee it won’t kill anybody, it’s still going to constantly get confused and cause traffic jams.
To get those last few nines of reliability—to go from 99 percent success to say 99.999 percent—a system needs to have a fairly sophisticated understanding of the world. It needs to not only know where its own lane is, but also when it’s ok to leave its lane to get around a parked car or construction site. It needs to be able to recognize pedestrians, cyclists, and construction workers—and predict their behavior. I suspect that in practice, the work required to make a self-parking system really good wouldn’t be that much less than building a full-blown robotaxi service.
Because it’s so hard to achieve those last few nines of reliability, almost every self-driving project relies on occasional intervention by remote human operators. Most of the time, Waymo’s driverless vehicles are truly driverless. But once in a while—the exact frequency is a closely guarded secret—a Waymo vehicle will find a situation it doesn’t understand and “phone home” for guidance. The goal is for the frequency of these interventions to decline over time as Waymo’s technology improves.
One consequence is that early driverless systems will all face non-trivial ongoing costs to employ remote operators. This means automakers would need to ask customers to pay a monthly fee, which might be a hard sell.
This is one reason I think fully driverless technology pretty much has to be introduced first as a stand-alone service, not as an add-on feature customers buy with their cars. Last week, I wrote about about one “easy” self-driving service that does seem to be gaining traction: Starship’s food delivery robots. These robots are so small, and travel so slowly, that there’s very little worry about them injuring or killing anybody, and not even that much worry about them getting in people’s way.
Is more inflation ahead?
Mindtools Sharpenter asks: “You (or at least your publication via Alan) made the claim a while back that low inflation is here to stay for the long-term, even if not for the short-term. All manner of other prognosticators are now baking in the opposite prediction: that we’re in for a decade of high inflation. Do you think you were wrong then or that the other prognosticators are wrong now?”
The prediction I remember Alan making was that interest rates would stay low. My guess is that over the long run, Alan’s view will prove correct. He argued that interest rates are falling because as a society we’ve grown older, wealthier, and less equal. Nothing that’s happened in the last year has changed those fundamentals, so my best guess is that interest rates will come back down over time. But I don’t have a strong view about whether that will take two years or 20 years.
As for inflation, I’ve been surprised at how high inflation has gotten, and I’m reluctant to make a new prediction that will probably look dumb a year from now. So I’ll just note that markets currently expect inflation to be 2.4 percent over the next five years and 2.3 percent over the next ten years. If I had a gun to my head, that’s the forecast I’d make. However, I can easily imagine it being significantly wrong in either direction.
Why I’m not worried about the robot apocalypse
Walter Frick (check out his economic forecasting newsletter) asks: “What do you think about the topic of AI safety? A seemingly growing number of prominent people are worried that AI poses a massive risk to humanity's future—not just because of biased algorithms or technology-induced unemployment but because they worry AI will take over / run amok / turn us all into paperclips. Do you share these concerns?”
I think AI safety advocates dramatically overrate the value of intelligence for achieving power. The smartest people on the planet usually don’t have a significant amount of power—they’re more likely to be college professors or novelists than CEOs or members of Congress.
Think back to the Manhattan project: in the late 1930s, some of the world’s smartest physicists realized that it would be possible to build an atomic bomb. But their next step wasn’t to build a bomb in their garage so they could personally take over the world. That wasn’t an option because it took a lot more than raw intelligence to build a bomb. It took thousands of workers and millions of dollars of investment—resources on a scale that only the federal government could mobilize.
I think the same basic point applies to a hypothetical super-intelligent AI. Any plan for world domination is going to require command over physical resources so the AI can build a robot army or hypersonic missiles or whatever. But if an AI starts hiring thousands of people to build killer robots, the rest of us will notice and put a stop to it—by force if necessary—long before the project gets far enough to pose a serious threat.
And without assistance manipulating the physical world, there’s just not that much a super-intelligent AI can accomplish. Here’s another way to see this: The US government has thousands of brilliant hackers who spend all their time trying to figure out how to do things like sabotage Iran’s nuclear program.
If the NSA had a larger or smarter workforce, it could probably accomplish more attacks like this and cause more headaches for the Iranian government. But no matter how many brilliant hackers the NSA hires, it’s never going to be able to take over Iran by purely electronic means. To do that you’d need a lot of “boots on the ground.”
A super-intelligent AI seeking to take over the world would face this same kind of practical constraint. It could certainly cause chaos by taking down websites and financial networks. Maybe it could trigger malfunctions at power plants and factories. But the power to annoy and inconvenience people is far short of the power to gain control in the physical world.
I think AI safety advocates would say that my argument might apply to humans with ordinary intelligence, but not to systems with super intelligence. But this just seems like magical thinking. If Albert Einstein had been ten times smarter (whatever that means), he still wouldn’t have been able to build an A-bomb. Even “super-intelligent” NSA hackers wouldn’t be able to topple the Iranian government from their desks in Fort Meade. Intelligence can be quite useful, but most problems can’t be solved with intelligence alone.
Explaining my chart posts
Sean Trott (check out his Substack about language models and machine learning) asks “how do you go about the early stages of research and planning for a quantitative post like 14 charts that explain America’s inflation mess or 24 charts that show we’re (mostly) living better than our parents? Did you come across some of these metrics elsewhere and decide to explore them more in-depth? How much exploration do you do that doesn't lead to something tangible or interesting? Is there a stock set of datasets that you know to turn to or do you also have to search for those pretty much from scratch?”
Thanks for asking about these posts! They are a lot of work, but readers seem to like them. My process for making them happens in three phases:
First, I’ll pick a broad theme (like “living standards” or “inflation”) and then over a month or two I’ll keep an eye out for interesting charts or data sets that fit the theme. I might find an interesting chart in a tweet, in someone else’s Substack post, or in an economics paper I’m reading for some other reason.
Second, I’ll spend a week or two actively hunting for data sets. I’ll brainstorm data that might illuminate the theme and then hunt around for available data sources. Sometimes a government agency has the data available for download (I rely heavily on FRED). Other times, I’ll email an academic researcher or a private organization to ask for the data. I also sometimes go back and update charts I created for earlier stories.
Finally, once I’ve got a pretty good lineup of charts, I try to organize them into a coherent narrative. Often during this process I’ll think of a few additional charts that would fill holes in the narrative, and I’ll hunt around for data that could fill in these gaps.
To be honest, I don’t do a whole lot of in-depth data exploration. Most of the time, someone else has already done the analysis. I think I add value in two ways:
I’m an efficient information scavenger: I consume information from a lot of sources and have a good eye for data would make a good chart. I’m also willing to do the legwork of emailing someone to ask for data, or extracting data that’s available in an inconvenient format like an old catalog.
I think I’m pretty good at presenting data in a clear and compelling way. A lot of charts out there are either way too complicated or not labeled well. I try to reduce the number of elements in each chart to the bare minimum so readers can understand it at a glance.
Here’s an example. When I was working on my living standards piece, I asked an automotive journalist I knew who might have interesting data about the industry. He suggested talking to a researcher at the car shopping site Edmunds. Edmunds provided me data for one of my favorite charts in that piece, showing how car prices have changed over the last 20 years:
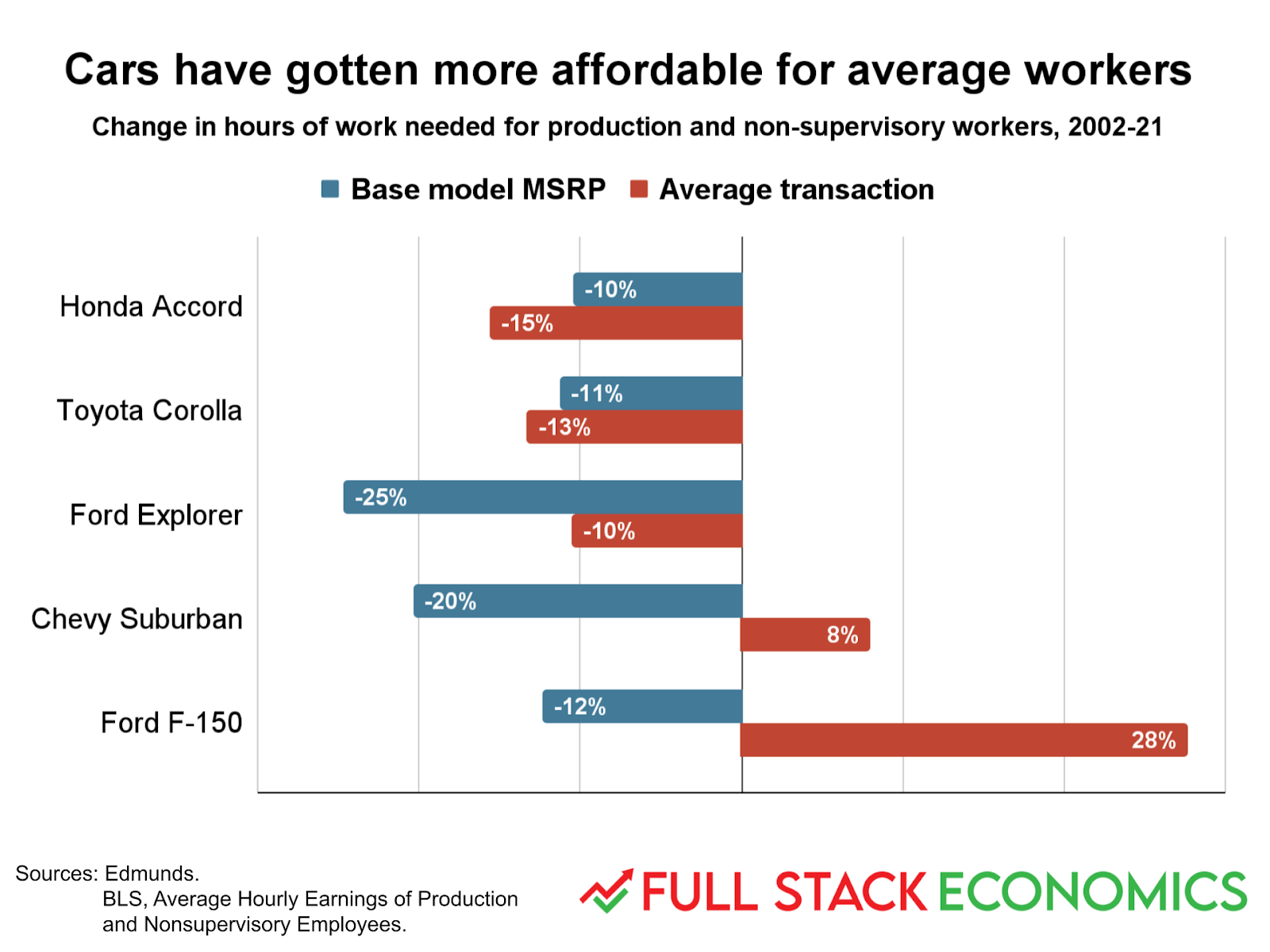
I initially formatted this as a line chart showing how prices for each of these vehicles changed from one year to the next. But that turned out to be way too much information to fit in a chart. So I switched to this bar chart format, which I think shows the key point—that economy cars have gotten cheaper, while customers have increasingly paid for upgrades to their trucks and SUVs—quite clearly.
Do you have a question you’d like me to answer? Please leave it in the comments below. But remember, the next mailbag post will be available to paying subscribers only.
I'd like to see another couple of articles on stay-at-dads and one soliciting and summarizing the wife's perspective. I'm in my 70s and I observe that society and relationships are changing. I'm particularly concerned about the declining number of marriages, increased co-habitation and fewer children. The woman-earner may be a step to correction. Mike Doherty
Thanks for the response! It's cool to read about the behind-the-scenes of how you make those charts.